Abstract
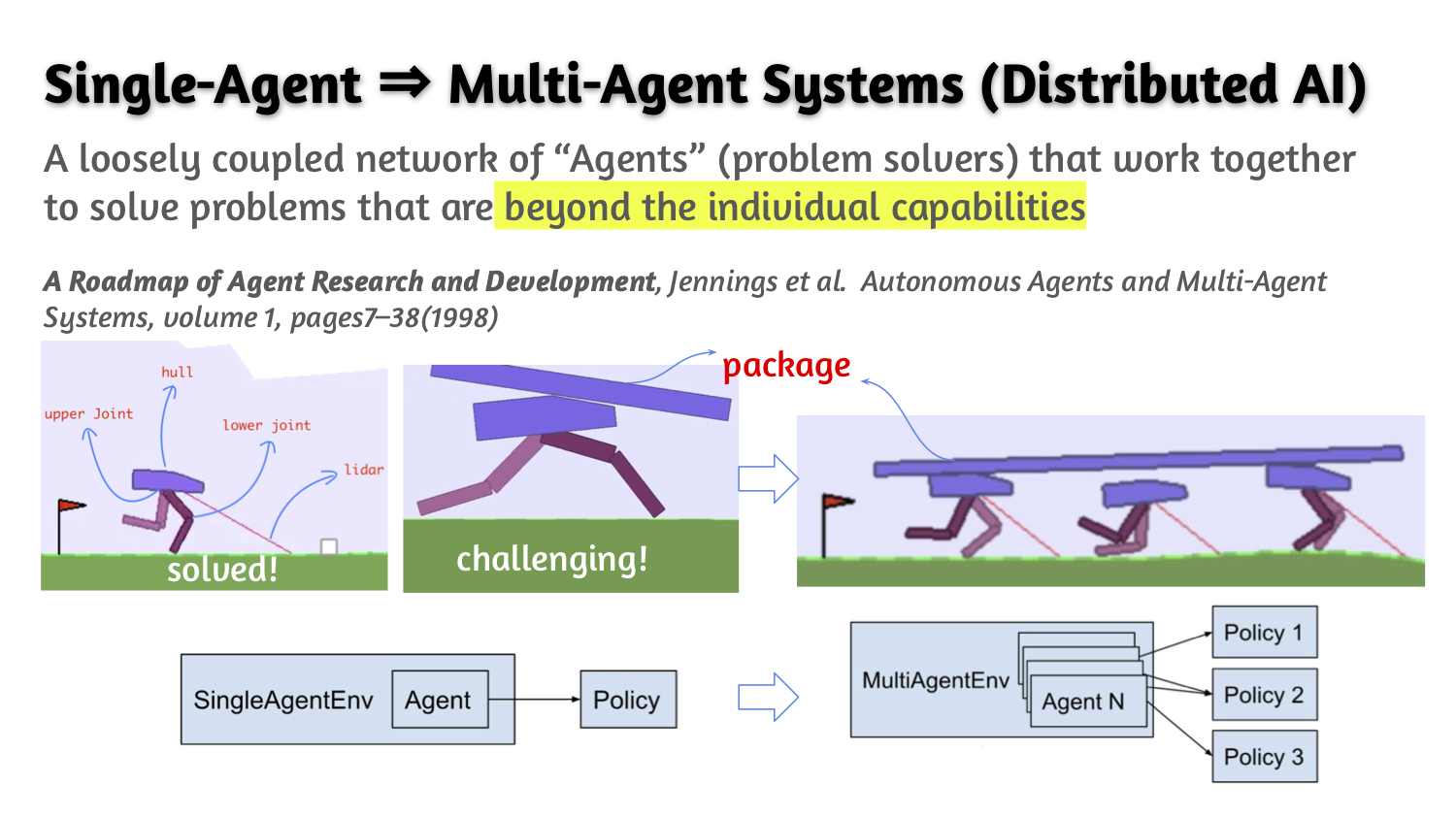
We apply the state-of-art performance Deep Reinforcement Learning (DRL) algorithm, Proximal Policy Optimization (PPO), to the minimal robot-legs locomotion for the challenging continuous and high-dimensional state-space multi-agent environments.
The discounted, accumulated reward (performance) of multi-agent DRL (MADRL) is maximized by hyperparameter tuning. Based on the comprehensive experiments with 2-10 multi-walkers environment, we found that
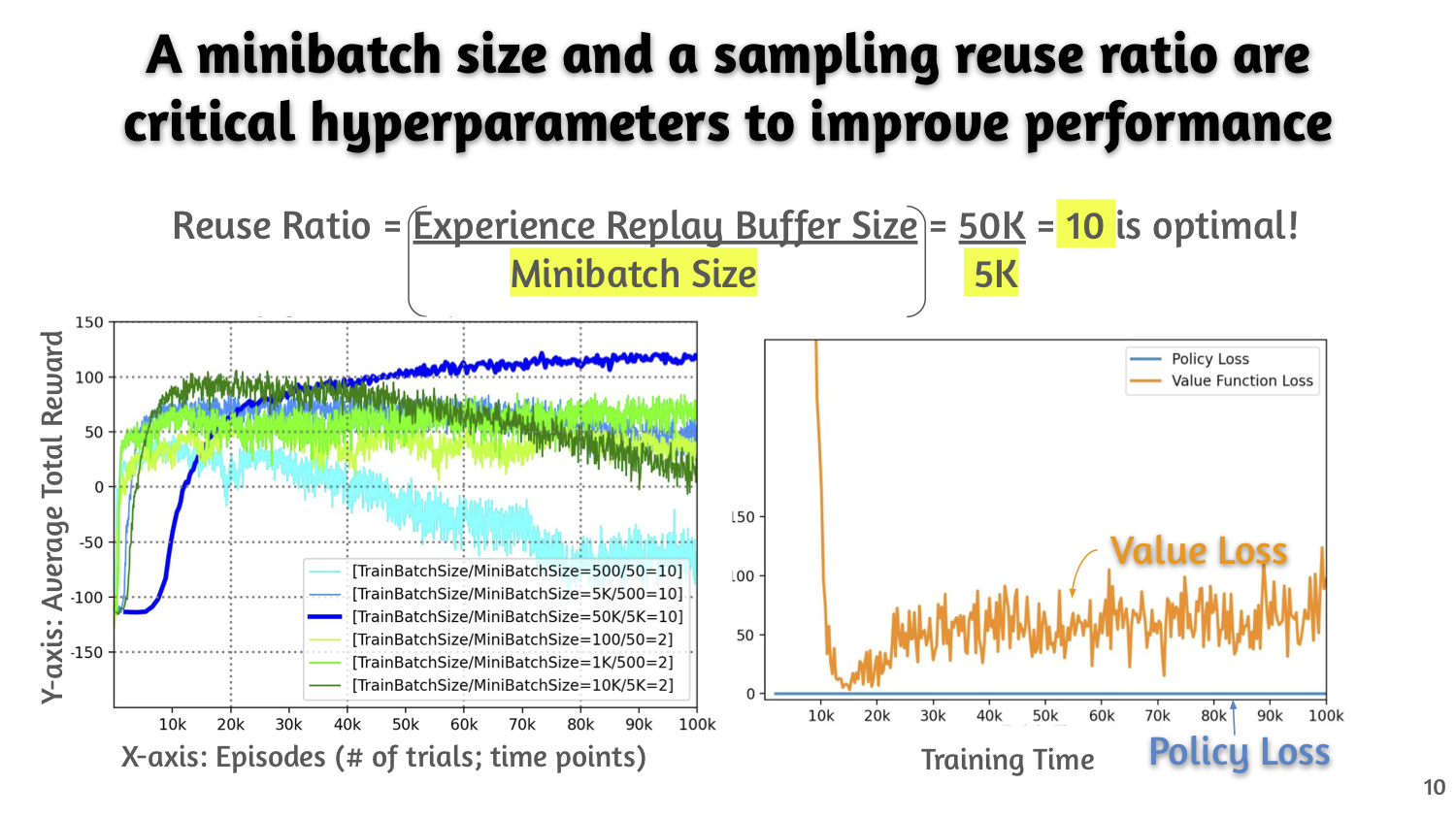
- A minibatch size and a sampling reuse ratio (experience replay buffer size containing multiple minibatches) are critical hyperparameters to improve performance of the PPO;
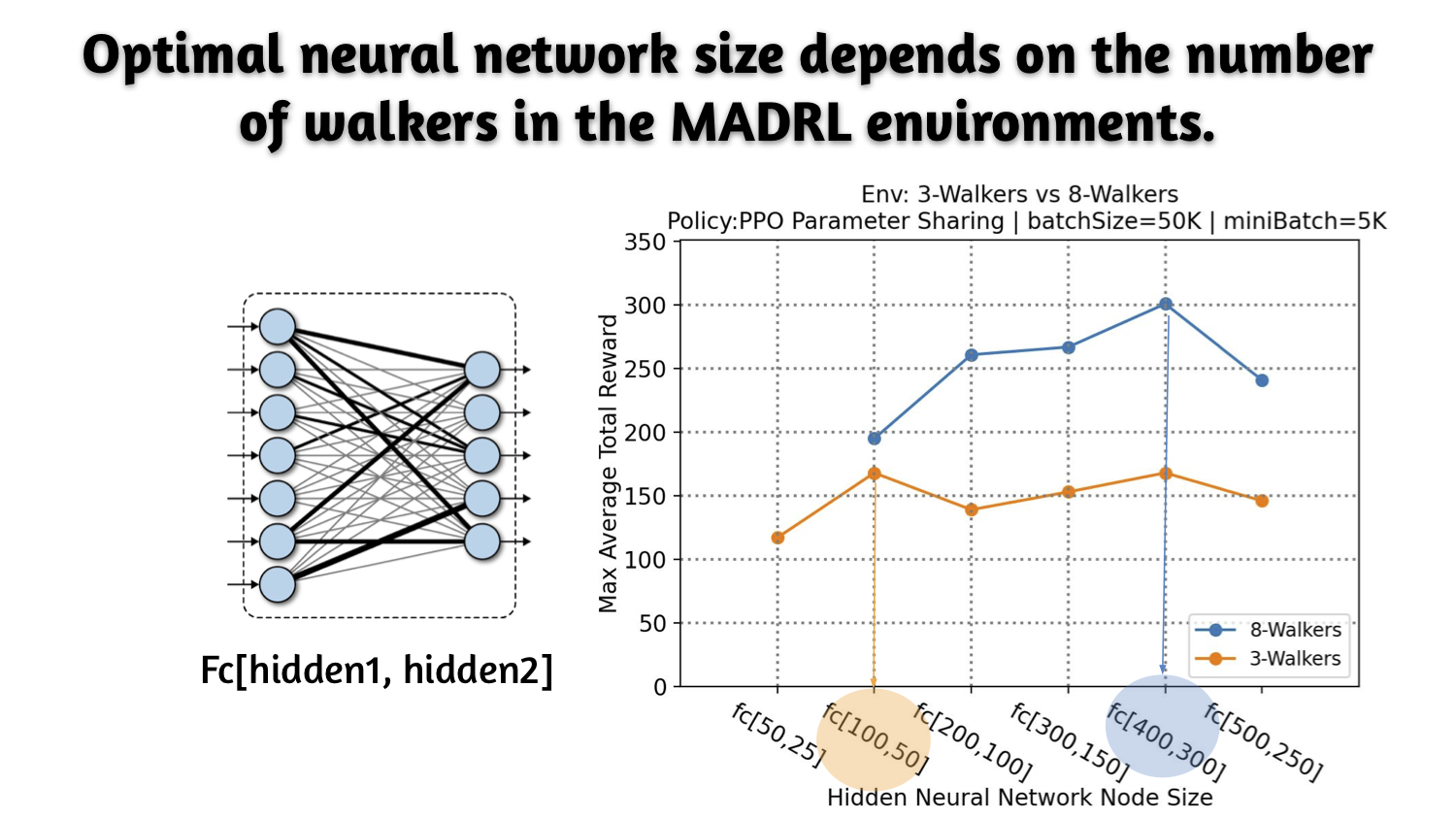
- Optimal neural network size depends on the number of walkers in the MADRL environments; and
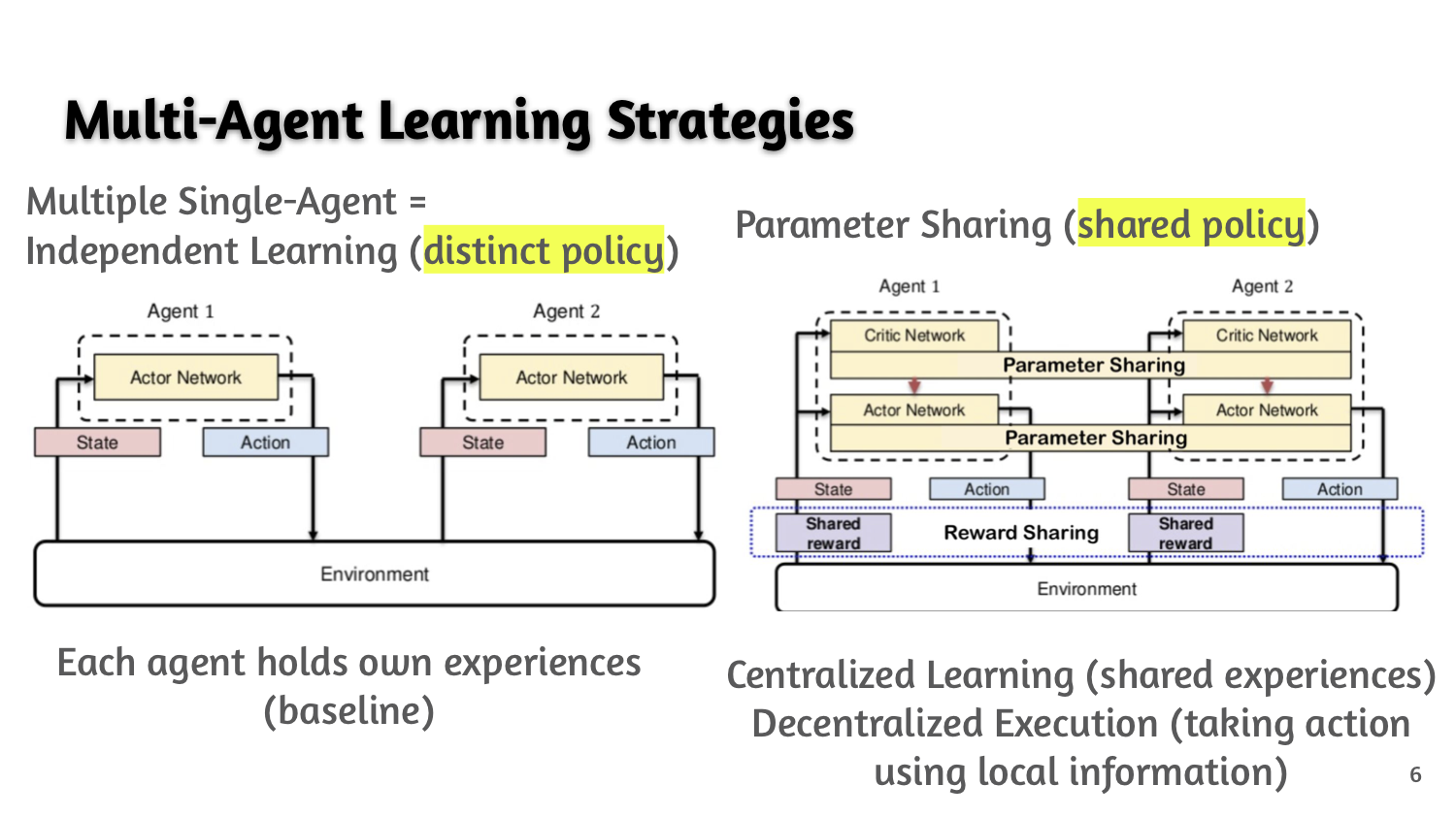
- Parameter sharing among multi-agent is a better strategy as a number of agent increases than fully independent learning for the MADRL in terms of comparable performance and improved efficiency with reduced parameters consuming less memory. This work showcases one instance of implicit cooperative learning of the MADRL.